Go言語のヒープに確保するデータの初期化コストについて調べてみた
2014.6.14追記
途中MakeContainer()/MakeContainerOneLine()がごちゃごちゃになっていたのを修正
golangでは、ヒープに置かれるデータの初期化方法によって内部の挙動が若干異なるみたい。
(環境はx86_64、go version 1.2.2)
違いが出たのは以下のコード。
構造体containerをヒープに確保してポインタ型の戻り値を返す関数を、3つの方法で定義している。
// alloc_overhead.go package main type container struct { v [64]byte } func MakeContainer() *container { c := container{} return &c } func MakeContainerOneLine() *container { return &container{} } func MakeContainerNew() *container { return new(container) } func main() { _ = MakeContainer() _ = MakeContainerOneLine() _ = MakeContainerNew() }
これを以下のコードでベンチマークをとってみる。
package main import ( "testing" ) func BenchmarkMakeContainer(b *testing.B) { for i := 0; i < b.N; i++ { _ = MakeContainer() } } func BenchmarkMakeContainerOneLine(b *testing.B) { for i := 0; i < b.N; i++ { _ = MakeContainerOneLine() } } func BenchmarkMakeContainerNew(b *testing.B) { for i := 0; i < b.N; i++ { _ = MakeContainerNew() } }
以下、ベンチマーク結果。
$ go test -bench . PASS BenchmarkMakeContainer 100000000 17.2 ns/op BenchmarkMakeContainerOneLine 50000000 25.9 ns/op BenchmarkMakeContainerNew 100000000 13.9 ns/op ok _/*/* 4.507s
この結果を見ると、new()するのが最も速く、1行でreturn &container{}した時が最も遅い結果になった。
アセンブラを読んでみた
なぜ速度に違いが出るのか、アセンブラを出力させて読んでみた。
x86_64の場合、アセンブラは
$ go tool 6g -S -S *.go
で出力できる。
以下、出力させたアセンブラから抜粋。(すべてのアセンブラ出力結果はGistを参照)
--- prog list "MakeContainer" --- 0000 (alloc_overhead.go:7) TEXT MakeContainer+0(SB),$80-8 0001 (alloc_overhead.go:7) FUNCDATA $0,gcargs揃0+0(SB) 0002 (alloc_overhead.go:7) FUNCDATA $1,gclocals揃0+0(SB) 0003 (alloc_overhead.go:7) TYPE ~anon0+0(FP){*"".container},$8 0004 (alloc_overhead.go:7) TYPE autotmp_0001+-64(SP){"".container},$64 0005 (alloc_overhead.go:8) MOVQ $type."".container+0(SB),(SP) 0006 (alloc_overhead.go:8) PCDATA $0,$16 0007 (alloc_overhead.go:8) CALL ,runtime.new+0(SB) 0008 (alloc_overhead.go:8) PCDATA $0,$-1 0009 (alloc_overhead.go:8) MOVQ 8(SP),AX 0010 (alloc_overhead.go:8) LEAQ statictmp_0002+0(SB),BX // 初期化データのアドレスをBXに設定 0011 (alloc_overhead.go:8) LEAQ autotmp_0001+-64(SP),BP 0012 (alloc_overhead.go:8) MOVQ BP,DI 0013 (alloc_overhead.go:8) MOVQ BX,SI // BXを入力に設定 0014 (alloc_overhead.go:8) MOVQ $8,CX // 以下3行で64byte分コピー 0015 (alloc_overhead.go:8) REP , 0016 (alloc_overhead.go:8) MOVSQ , 0017 (alloc_overhead.go:8) MOVQ AX,DI 0018 (alloc_overhead.go:8) MOVQ BP,SI // コピーされたアドレスを今度は入力に設定 0019 (alloc_overhead.go:8) MOVQ $8,CX // 以下3行で64byte分コピー 0020 (alloc_overhead.go:8) REP , 0021 (alloc_overhead.go:8) MOVSQ , 0022 (alloc_overhead.go:9) MOVQ AX,~anon0+0(FP) 0023 (alloc_overhead.go:9) RET , --- prog list "MakeContainerOneLine" --- 0024 (alloc_overhead.go:12) TEXT MakeContainerOneLine+0(SB),$16-8 0025 (alloc_overhead.go:12) FUNCDATA $0,gcargs揃1+0(SB) 0026 (alloc_overhead.go:12) FUNCDATA $1,gclocals揃1+0(SB) 0027 (alloc_overhead.go:12) TYPE ~anon0+0(FP){*"".container},$8 0028 (alloc_overhead.go:13) MOVQ $type."".container+0(SB),(SP) 0029 (alloc_overhead.go:13) PCDATA $0,$16 0030 (alloc_overhead.go:13) CALL ,runtime.new+0(SB) 0031 (alloc_overhead.go:13) PCDATA $0,$-1 0032 (alloc_overhead.go:13) MOVQ 8(SP),BX 0033 (alloc_overhead.go:13) MOVQ BX,DI 0034 (alloc_overhead.go:13) CMPQ BX,$0 0035 (alloc_overhead.go:13) JNE $1,37 0036 (alloc_overhead.go:13) MOVL AX,(BX) 0037 (alloc_overhead.go:13) MOVQ $0,AX // AXに0を設定 0038 (alloc_overhead.go:13) MOVQ $8,CX // 以下3行で64byte分0をセット 0039 (alloc_overhead.go:13) REP , 0040 (alloc_overhead.go:13) STOSQ , 0041 (alloc_overhead.go:13) MOVQ BX,~anon0+0(FP) 0042 (alloc_overhead.go:13) RET , --- prog list "MakeContainerNew" --- 0043 (alloc_overhead.go:16) TEXT MakeContainerNew+0(SB),$16-8 0044 (alloc_overhead.go:16) FUNCDATA $0,gcargs揃2+0(SB) 0045 (alloc_overhead.go:16) FUNCDATA $1,gclocals揃2+0(SB) 0046 (alloc_overhead.go:16) TYPE ~anon0+0(FP){*"".container},$8 0047 (alloc_overhead.go:17) MOVQ $type."".container+0(SB),(SP) 0048 (alloc_overhead.go:17) PCDATA $0,$16 0049 (alloc_overhead.go:17) CALL ,runtime.new+0(SB) 0050 (alloc_overhead.go:17) PCDATA $0,$-1 0051 (alloc_overhead.go:17) MOVQ 8(SP),BX 0052 (alloc_overhead.go:17) MOVQ BX,~anon0+0(FP) 0053 (alloc_overhead.go:17) RET ,
このアセンブラ出力を見ると、それぞれデータの生成方法が異なっているようだ。
MakeContainer()では、new()で確保された領域にstatic領域に確保された初期化データ(statictmp)をmemcpy(MOVSQ命令)してデータを生成しているのに対し、
MakeContainerOneLine()では、new()で確保された領域をmemset(STOSQ命令)してデータを生成している。
MakeContainerNew()は1番シンプルで、new()して領域を確保するだけだ。
MakeContainer()の方がMakeContainerOneLine()よりも速い理由は、MOVSQ命令がSTOSQ命令よりも高速に実行できるためだと思う。
Intelのx86最適化マニュアル(Table C-16. General Purpose Instructions)を見ると、MOVSBの命令レイテンシが0.5なのに対し、STOSBの命令レイテンシは2と、4倍のレイテンシになっている。(参照箇所が正しいか自信がないが…)
MakeContainer()ではMOVSQ命令が 8 × 2 回、MakeContainerOneLine()ではSTOSQ命令が 8 × 1 回行われている。
そのため、MOVSQ/STOSQ命令がMOVSB/STOSB命令と同じ命令レイテンシだと仮定すると、MakeContainer()は 0.5(MOVSQ) × 2 = 1 、MakeContainerOneLineは 2(STOSQ) × 1 = 2 となり、MakeContainerOneLine()の方が処理時間がかかることになる。
バイナリサイズの違い
MakeContainer()とMakeContainerOneLine()、MakeContainerNew()のそれぞれを使った場合に生成されるバイナリサイズの違いについてだが、MakeContainer()だけが他の2つよりもサイズが大きくなる。
$ ls -l -rwxr-xr-x 1 ryochack staff 564960 Jun 8 18:11 MakeContainer* -rwxr-xr-x 1 ryochack staff 564912 Jun 8 18:11 MakeContainerNew* -rwxr-xr-x 1 ryochack staff 564912 Jun 8 18:11 MakeContainerOneLine*
これは、先ほどに書いたように、MakeContainer()のような以下の書き方をすると、ビルド時に初期化用の値がstatic領域(statictmp)に確保されるためだろう。
以下コマンドでバイナリファイルのデータ配置も見てみたが、MakeContainer()の時のみ statictmp が配置されているのを確認した。
$ go tool 6l -a *.6
まとめ
golangでデータをヒープに確保するときは、内部的にnew()が呼ばれる。
複合リテラル記法を使うと、new()された後に memset/memcpy のいずれかの処理が走る。
おそらく、複合リテラル記法で初期値を指定しないフィールドに関しては、暗示的に0を指定されたことになる。
golangのnew()は、値がゼロ初期化されていることが保証されているので、&container{}みたいな書き方をすると、new()でゼロ初期化された後に再度ゼロが設定される挙動になるようだ。
①new()した後にmemcpy()の挙動。バイナリサイズが他2つよりも大きくなる。②より速く、③より遅い。
func MakeContainer() *container { c := container{} return &c }
②new()した後にmemset()の挙動。最も遅い。
func MakeContainerOneLine() *container { return &container{} }
③new()のみの挙動。最も速い。
func MakeContainerNew() *container { return new(container) }
参考
x86_64の命令セットと最適化マニュアル
Go言語での複数チャネルからのメッセージ受信
Goではgoroutineを使うことで並行処理をとても簡単に実行できるが、複数goroutineとの同期が難しい。
そこで、複数走らせたgoroutineのメッセージを用いた同期方法について考えてみた。
以下のように、複数のチャネルからのメッセージを受信する必要がある時、どうやって各goroutineからのメッセージを、同時に、最後まで、受信すればいいか?
func f(msg string, n int) chan string { ch := make(chan string) go func() { for i:=0; i<n; i++ { ch <- msg + " please!" } close(ch) }() return ch } func main() { ch1 := f("beer", 4) ch2 := f("juice", 2) ch3 := f("water", 1) // ここでch1, ch2, ch3のメッセージを受信したい // それぞれのchannelは非同期に動いていて // 終了までに送られてくるメッセージ数も異なる … fmt.Println("exit") }
selectによる複数メッセージ受信
selectを使って複数チャネルからのメッセージ受信を同時に行う。
チャネル通信の完了は、完了通知用のチャネルを生成して通知する。
Go Playgourndで実行
受信部分をgoroutine化して複数メッセージを非同期受信
メッセージの受信処理を無名関数でラッピングして、チャネル毎にgoroutine化して実行。
range節でチャネル受信をループ化しているため、チャネルがcloseされるとループが終了する。
main関数での受信完了同期にはWaitGroupを使っている。
Go Playgourndで実行
受信部分をgoroutine化する方法は、main関数でメッセージを受け取ってない。
reporterからmainに処理結果を渡さなくちゃいけないときには別途チャネルが必要になるけれども、メッセージの値を表示させるだけならコードがシンプルになっていい。
追記
以下のようにWaitGroup.Wait()をgoroutine化して待つ方法もある。
参考
Go言語でmmapシステムコールを使ったファイル読み込みの高速化検討とC言語のコンパイラの話
2013.10.14 追記
@kazuho さんからご指摘いただきました!
mmapのほうがreadより速いという迷信について - kazuhoのメモ置き場 -
長いタイトル…。
こないだ書いたgorepっていう検索ツール、もうちょっと速くしたいなと思ってファイル読み込みの部分をmmap()で置き換える検討中。(ちょっぱやのagもmmap()を使っている)
mmap()での高速化確認用にCとGoで簡単なコード書いて実験していたら、以下のことがわかった。
処理速度比較の準備
比較用に書いたのは、open()/read()と、open()/mmap()、そしてfopen()/fread()を行うCとGoのコード。
Goのfread()は、bufio.Read()で置き換えている。
- C:
- Go
- open/read https://gist.github.com/ryochack/6021257
- open/mmap https://gist.github.com/ryochack/6020725
- fopen/fread(bufio.Read) https://gist.github.com/ryochack/6021642
Cのコンパイラには以下3つを用意し、最適化オプションは全て-O3を使用。(実行環境はMac OS X Lion / MacBook Late2008)
- LLVM-GCC4.2 (Xcode付属)
- GCC4.9
- LLVM-Clang3.4
GoはVersion 1.1.1を使用。
ビルドしてできたそれぞれの実行ファイルに、以下の方法で用意した1GBのファイルを読み込ませて、処理時間を測った。
入力データ作成 (1GB) $ dd if=/dev/random of=huge.dat bs=512 count=2097152
実行結果

処理時間の詳細。(10回実行した平均)
| open+read | open+mmap | fopen+fread | |
|---|---|---|---|
| LLVM-GCC4.2 | 2.7149 [s] | 1.8465 [s] | 2.7040 [s] |
| GCC4.9 | 2.8684 [s] | 2.0105 [s] | 2.8631 [s] |
| LLVM-Clang3.4 | 1.6956 [s] | 0.8303 [s] | 1.6946 [s] |
| Go Compiler (ver1.1.1) | 2.4115 [s] | 1.4925 [s] | 2.3830 [s] |
期待どおりに、CでもGoでもopen/readよりもopen/mmapの方が速くなってる。
で、コンパイラによる違いについて。
Clangビルドでの処理速度がズバ抜けてる…!
Goの処理速度がLLVM-GCCとGCCよりも速いってのも驚き。
Cのコードがコンパイラによってここまで極端に速度の差が出るとは思っていなかった。
参考
C言語とGo言語で標準出力が端末を参照しているかどうかを判定する
標準出力のディスクリプタを取得して、それが端末を参照しているかどうかを判定する。 使いどころは端末に出力する時と、ファイルにリダイレクト出力する時とで表示の仕方を変えたいとき。
例えば、以下のページの方法でターミナルの文字をカラーにできる。
だけど、これをファイルにリダイレクト出力するとエスケープシーケンスまで記録されてしまい、非常に見づらくなる。
そこで、標準出力がどこに出力されるかを判定し、カラーのON/OFFを切り替える処理を入れるようにしたい。
出力先が端末かどうかの判定は、Cだとこう書く。
#include <stdio.h> #include <unistd.h> int main() { int fd = fileno(stdout); int isTerminal = isatty(fd); printf("fd=%d, isTerm=%d\n", fd, isTerminal); return 0; }
Goだとこう書く。
Cのisatty()の代わりになる関数が公式パッケージにはなかったので、
http://godoc.org/code.google.com/p/go.crypto/ssh/terminal
のIsTerminal()を使用。
package main import ( "fmt" "os" term "code.google.com/p/go.crypto/ssh/terminal" ) func main() { fd := os.Stdout.Fd() isTerminal := term.IsTerminal(int(fd)) fmt.Printf("fd=%v, isTerm=%v\n", fd, isTerminal) }
agはどうやって表示の切り替えをやってるんだろうとコード調べたのがきっかけ。 勉強になった。
参考
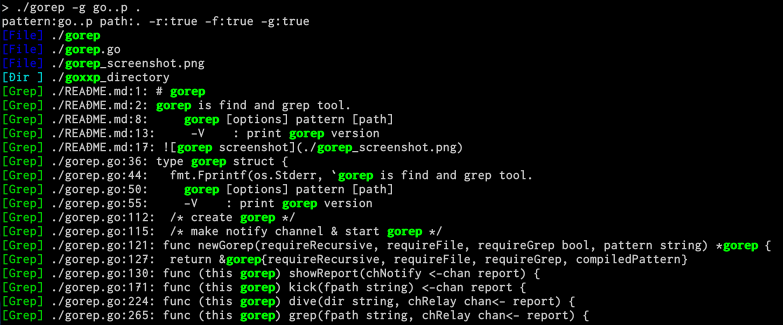
Go言語でgorepっていう検索ツール書いた
ディレクトリ名やらファイル名やらGrep検索やらを一緒くたに正規表現で検索する"gorep"っていうツール書いた。
https://github.com/ryochack/gorep
以下のコマンドを打ち込むと、カレントディレクトリ以下から再帰的にgo..pにマッチするディレクトリ、ファイル、テキストファイルの文字列を表示する。
$ gorep -g go..p .
-gをつけるとgrep検索が有効になる。
Windowsで気軽に検索できるツールが欲しいってのがモチベーションだったけど、まだWindowsで動作検証していないっていう体たらく。